uni2ascii וascii2uni להמיר בין UTF-8 Unicode וכל מגוון שווה ASCII 7 סיביות כולל: הקסדצימלי ואזכור דמות מספרית עשרוני HTML, u-בריחות, הקסדצימלי הסטנדרטי, והקסדצימלי גלם.
שווה ASCII כאלה הם שימושיים כאשר כוללים טקסט Unicode במקור תכנית, בעת הזנת טקסט לתוכניות אינטרנט שיכול לטפל בערכת תווי Unicode אבל לא 8 ביט בטוח, וכאשר באגים.
Unicode בורח זמין הם:
- אזכור מספרי הקסדצימלי HTML אופי (לדוגמא)
אזכור HTML עשרוני אופי מספרי (למשל ȳ) -
- U-בריחות, כמו שימוש בפייתון (למשל u00E9)
- U-בריחות בתוך BMP ו- U-הבריחה מעבר BMP, למשל u00E9 אבל U00010024.
- U -escapes (למשל U 00E9)
- U-בריחות (למשל U00E9)
- U-בריחות (למשל u00E9)
- U-בריחות בתוך סוגריים זווית (למשל)
- X-בריחות (למשל x00E9)
- X-בריחות עם פלטה (למשל x {} 00E9)
- הקסדצימלי סטנדרטי (למשל 0x00E9)
- הקסדצימלי גלם (למשל 00E9)
uni2ascii מקבל דגל שורת פקודת קביעה האם ליצור אותיות רישיות AF או נמוך יותר במקרה AF כספרות הקסדצימלי מאז כמה תוכניות מסוימות קיבלו רק אחד או אחר. ascii2uni מקבל גם.
במקרה של uni2ascii כברירת מחדל, רק דמויות מחוץ לטווח ASCII מומרות. גם אם תווי ASCII גם הומרו, שורות החדשות נשמרות, אלא אם כן ההמרה שלהם היא במפורש ביקשה. דמויות שטח גם נשמרות, אלא אם כן המרה במפורש ביקשה. במקרה של דמויות שלוש שאינו ASCII השטח (שטח אתיופי מילה, חלל אוהם, ומרחב אידיאוגרפי), אם תווי רווח אינם מומרים, אלה מוחלפים במרחב ASCII (0x20) כדי לשמור על התפוקה ב7- טווח ASCII קצת.
חבילה זו כוללת ארבע תוכניות. התכנית העיקרית היא uni2ascii. זה כתוב ב- C וחייב להיות הידור. uni2html.py הוא קודמו לuni2ascii. ככתוב בפייתון, זה לא צריך להיות הידור וצריך לרוץ על כמעט כל מחשב נוכחי. uni2ascii הוא אחרת מעולה שב:
- זה יוצר מגוון רחב יותר של פורמטי פלט.
- זה הוא כ 20 פעמים מהר יותר.
- זה מטפל בקלט בטווח Unicode 32 ביט המלא. לעומת זאת, uni2html מטפל רק
יסוד רב מטוס (מטוס 0) כי כיום פייתון מייצגת טקסט מוצפן Unicode הפנימי באמצעות מספרים שלמים 16 סיביות. אם יש לך טקסט ב, למשל, לינארי B או אוגריתית, אתה צריך uni2ascii.
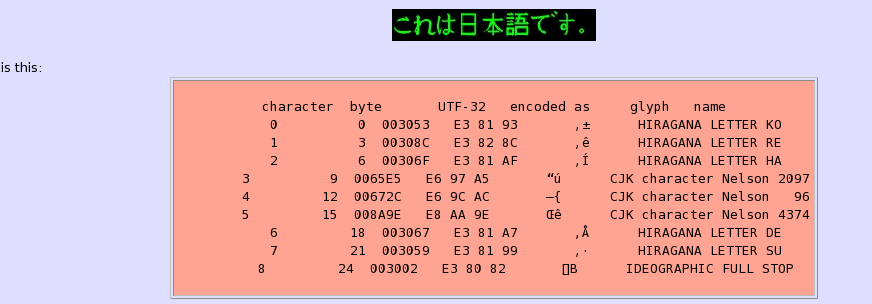
הוא עושה עבודה טובה יותר של דיווח שגיאות. אם הוא נתקל בשגיאה בקלטה, כגון-נוצר mal UTF-8, הוא מדווח את מיקומו של השגיאה הן במונחים של ספירת האופי מתחילת הקובץ (החל מ 0) ובמונחים של ספירת הבתים מההתחלה של הקובץ (גם מתחיל ב 0). (ספירת תווים וספירת בתים הן בדרך כלל לא אותו הדבר מאז אופי קידוד UTF-8 תופס מאחד עד ארבעה בתים.) דיווחי הגרסה פייתון רק ספירת האופי. uni2ascii גם מספק מידע על אופי השגיאה.
התכנית השלישית, ascii2uni, היא ההופכי של uni2ascii. היא מקבלת טקסט המכיל מגוון רחב של ייצוגי ASCII של תווי Unicode ומייצרת UTF-8 Unicode.
התכנית הרביעית, ascii2uni.py, קוראת ASCII 7 סיביות המכיל Unicode, כמו שימוש בפייתון וTcl, וממיר אותו ל- UTF-8 Unicode-נמלט u. זוהי התכנית המקורית של שascii2uni היא הכללה
מה חדש בהודעה זו:.
- באג
קבוע בuni2ascii שבמקרים מסוימים ספירת subsitution הייתה גבוהה מדי, תיקון באג # דביאן 626,268.
- טלוא להתמודד עם המצב בNetBSD שחסר getline.
- מובהר בסמנטיקה של אפשרות טהורה כהמרת תווי ASCII בטווח למעט שטח ושורה חדש. תוקן הבאג שבי זה לא יושם כראוי לסוגי UTF8.
מה חדש בגרסה 4.17 :
- נוסף לuni2ascii המרות לשווים ערך ASCII הקרוב הבאות: U 2022 כדור ל'O ', U + 00B7 נקודת אמצע לתקופה, + 0085 השורה הבאה U לשורה חדשה, מפריד קו U + 2,028 לשורה חדשה.
מה חדש בגרסת 4.16:
- פורמט Q עובד שוב בascii2uni
מה חדש בגרסת 4.15:
- endian.h שמם לu2a_endian.h לחסל סכסוך עם endian.h החיצוני.
- עותק הוסר מgetline גנו מascii2uni.c כפי שהוא רגיל כמו של POSIX2008.
מה חדש בגרסת 4.14:
- תוקן באג שהפריע לשימוש בפורמט ש בuni2ascii.
- תוקן הבאג הוסיף שבascification של U + 2,502 וU 2,503 + ציטוט כפול לתפוקה.
- תוקן באג שבי -A אפשרות S נוצרה & quot; המרה תווים & quot כל כך הרבה; קו עבור כל תו בשל עוזב בקוד ניפוי.
מה חדש בגרסת 4.13:
- קבוע שנגרם מספר מוגזם של דמויות שונה לASCII ל בדיווח.
מה חדש בגרסת 4.12:
- שני התוכניות מאפשרות כעת את שם קובץ קלט שיפורט ב שורת הפקודה ללא ניתוב מחדש.
מה חדש בגרסת 4.11:
- גרסה זו מוסיפה תמיכה ל& lt; XX & gt; & lt; XX & gt; ופורמטי uXXXX%.
מה חדש בגרסת 4.10:
- שחרור זה מתקן באג שגרם לטענת Y ל דגל -a של ascii2uni לא-אופ, ומתקן את דפי האדם ולעזור לטיעוני Y ו- Q לדגל -a לשתי התוכניות.
סיכומים
תגובות לא נמצא