
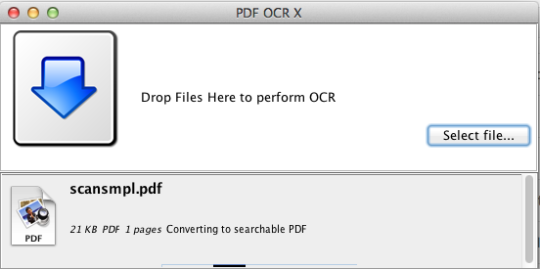
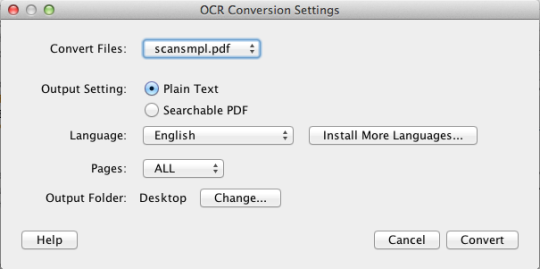
PDF OCR X הוא כלי גרור ושחרר פשוט עבור Mac OS X, הממיר את קבצי PDF ותמונות לתוך מסמכי PDF או טקסט לחיפוש. הוא משתמש בטכנולוגיה מתקדמת OCR (זיהוי תווים אופטי) כדי לחלץ את הטקסט של PDF (או תמונה) גם אם הטקסט הזה הוא הכלול בתמונה. תכונה זו שימושית במיוחד בהתמודדות עם קובצי PDF ותמונות שנוצרו באמצעות פונקציית Scan-to-PDF במעתיק סורק או צילום. תומך מעל 60 שפות עבור OCR. מנוע ה- OCR מבוסס על Tesseract. מהדורת הקהילה תומכת במסמכי PDF של דף יחיד (או בדף הראשון של קובצי PDF מרובי עמודים). לקבלת תמיכה מרובת עמודים ב- PDF, עליך לשדרג למהדורה הארגונית.
מה חדש במהדורה זו:
גרסה 2.1.1 מוסיף תמיכה למוג'בה , ומשפר את ממשק המשתמש על תצוגות הרשתית.
מה חדש בגירסה 2.0.8:
בעיה קבועה בטיפול ב- PDF עם סיבוב. >
מגבלות :
מהדורת הקהילה מוגבלת למסמכי PDF ותמונות בודדים.



תגובות לא נמצא